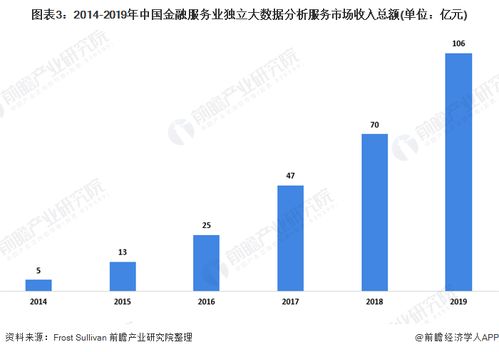
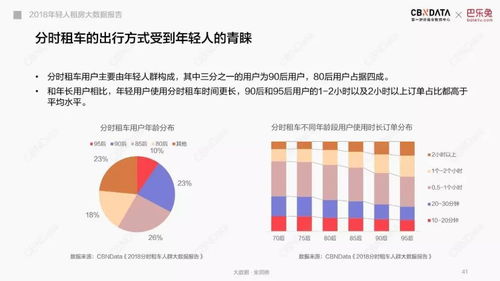
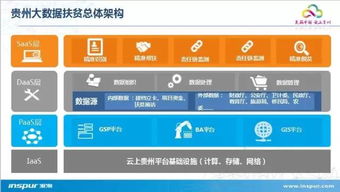
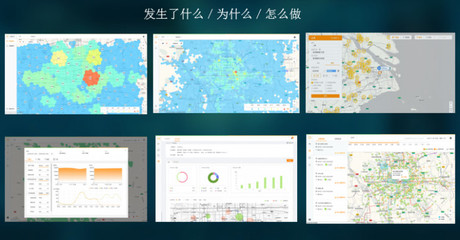
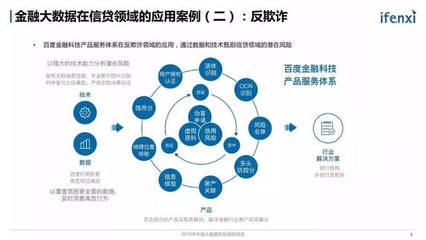
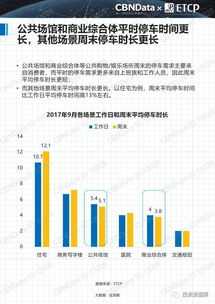
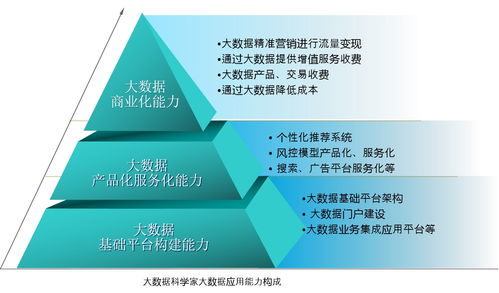
2016年上半年,大数据领域风云激荡,技术与应用的结合日益紧密。一批创新性强、实用性高的产品与服务崭露头角,不仅推动了数据处理能力的边界,更在实时分析、机器学习、云服务及数据安全等方面带来了革命性体验。以下盘点了上半年十款最具代表性的酷炫大数据产品与服务,它们共同勾勒出当时数据智能生态的蓬勃图景。
- Apache Spark 2.0(预览版):作为大数据处理框架的明星,Spark 2.0预览版在2016年上半年发布,其核心亮点在于引入了全新的“结构化API”(DataFrame和Dataset的统一),并大幅提升了性能与易用性,让流处理和批处理的编程模型更加一致,被誉为一次重大飞跃。
- Amazon Athena:亚马逊AWS推出的一款交互式查询服务,无需管理基础设施,即可使用标准SQL直接分析存储在S3中的数据。它以其无服务器架构和按扫描数据量付费的模式,极大降低了即席查询的门槛和成本,令人耳目一新。
- Google Cloud Dataproc:谷歌云平台推出的托管式Spark和Hadoop服务。它允许用户在几分钟内创建可定制的集群,并集成了谷歌云的其他服务(如BigQuery、Cloud Storage),因其快速的启动速度和精细的成本控制(支持按秒计费)而备受青睐。
- Microsoft Azure Data Lake Store & Analytics:微软推出的超大规模数据湖存储与分析服务。Data Lake Store提供无限制的存储,支持任何类型的数据;而Data Lake Analytics则提供了基于YARN的、高度可扩展的分布式分析服务,使用类似SQL的U-SQL语言,简化了大数据处理流程。
- Tableau 10.0:数据可视化领域的领导者Tableau发布了其10.0版本,新增了跨数据库联接、簇分析、灵活的时间序列分析等功能,并增强了与Spark、Hadoop等大数据平台的集成,使得从大型数据集中快速发现洞察变得更加直观和强大。
- Cloudera Data Science Workbench:Cloudera推出的自助式数据科学工作台,允许数据科学家使用自己喜欢的开源工具(如Python、R、Scala)直接在安全的Hadoop集群上进行探索、实验和模型部署,打破了数据科学与生产环境之间的壁垒。
- Splunk Machine Learning Toolkit:Splunk将其强大的机器学习和预测分析能力打包成工具包,使普通用户也能在Splunk平台上利用流行的算法库(如Scikit-learn)来构建和部署机器学习模型,将机器学习无缝融入运维和业务分析场景。
- Talend Big Data Platform v6:Talend发布了其统一的大数据平台版本,提供了更丰富的组件和连接器,支持Spark Streaming、Storm等流处理框架,并通过图形化设计器大幅简化了复杂数据集成和数据质量作业的开发,提升了开发效率。
- Confluent Platform 3.0:基于Apache Kafka的Confluent平台推出了3.0版本,强化了Kafka作为实时数据流中枢的地位。新版本提供了更完善的Kafka Streams API(用于流处理)、更强大的Kafka Connect(用于数据集成)以及改进的管理控制台,助力企业构建实时数据管道。
- IBM Data Science Experience:IBM推出的云端协作式数据科学平台,集成了开源工具(如RStudio, Jupyter notebooks)和IBM Watson的数据分析服务。它强调团队协作和模型生命周期管理,旨在为数据科学家提供一个端到端的云端工作环境。
**:2016年上半年的这些产品与服务,清晰地呈现出几个关键趋势:云化与无服务器架构降低了使用门槛;实时流处理成为标配;数据科学与机器学习的平民化进程加速;SQL的复兴与统一的分析接口备受重视;可视化与交互体验**持续提升。这些创新不仅在当时酷炫,更为后续数年大数据技术的普及与深化奠定了坚实的基础,持续驱动着各行各业的数字化转型。